你的位置:NBA下注app中国官方下载 > NBA投注 >


大模子在AIME、IMO等高难度竞赛中拿奖拿得手,仿佛也曾进化出了“东说念主类最宽阔脑”。但与此同期,如若你问大模子:“离洗车店独一 50 米,我是开车去如故步碾儿去?”。这些堪称满分推理的模子,依然会一册正经地为你诡计导航线线。
这种看似知识丰富,但没学问的表象,恰是现时大模子评测的死穴:大模子天然擅长操心复杂的公式,却时常连一起通俗的逻辑题王人答分歧。
基于此,好意思团 LongCat 团队庄重发布 General 365。咱们发现, 在对 26 款主流模子的实测中,当今地表最强的 Gemini 3 Pro 准确率仅为 62.8%,而绝大多半模子以致没能摸到 60 分的合格线。
这份基准将焦点从“学科推理”拓展到“通用推理”,第一次了了地勾画出了现时大模子在通用逻辑推理上的果然才气鸿沟。

夙昔两年, 大模子推理评测高度采集在数学、物理、编程等依赖专科知识的任务上,头部模子在各大题库上以致迫临满分。 权衡词,学科推理得分高,并不即是通用推理强 ——高分可动力于模子对老师语料的暴力操心与时势匹配,而非可泛化的逻辑推演才气。现存通用推理基准(如BBH、BBEH)濒临两大瓶颈:任务模板化导致逻辑同质严重,性能饱和导致鉴识度断崖式下落。
General 365的遐想诡计由此明确: 将布景知识收场在K-12水平,显式解耦推理才气与专科知识,系统地评估模子在平时场景下的通用推理水平。 它具备五项中枢特征:
高各种性: 365说念原创种子题目及1095个彭胀变体,全面笼罩八大挑战类型,幸免重叠特征与死记硬背;
高挑 战性 : SOTA模子在此基准上也仅能拼凑合格;
聚焦推理 : 知识鸿沟严格收场在K-12,隧说念权衡逻辑推理,而非知识检索;
严格东说念主工质检: 全量题目均经由东说念主工审核,笼罩题目遐想、推理轨迹与最终谜底;
精确评分: 罗致搀杂律例与模子的打分智力,东说念主工抽样考据,评分准确率达99.6%。


要权衡通用推理,最初要明确它包含哪些中枢挑战?General 365 将其拆解为八个维度,每说念题至少对应其一:
复杂拘谨: 多条目交汇下的全局一致性惊叹;
分支与胪列: 解 空间的系 统性遍历与鸿沟笼罩;
时空推理: 空间干系与时间序列的动态推演;
递归与回溯: 假定—考据—推翻的迭代纠错;
语义搅扰: 进步领悟罗网,严格驯服题设律例;
隐式信息: 从碎屑萍踪揣度底层逻辑结构;
最优计策: 多 旅途决议中的遵循权衡与诡计;
概率与不细则性: 不十足信息下的概率揣度。
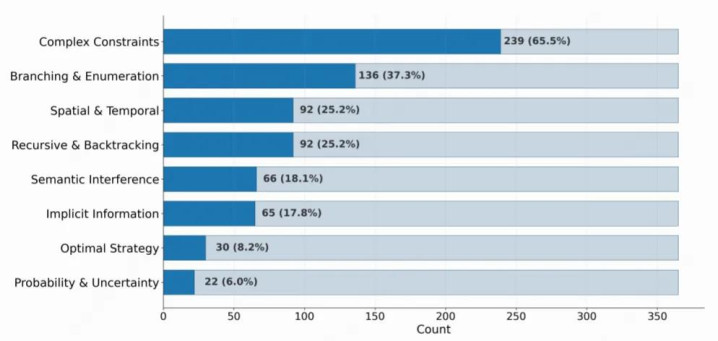
图1:八个类别的题目数目散播
如上图所示,“复杂拘谨类”题目占比最大,“概率与不细则性类”也包含超 20 说念题目,确保了每个维度王人有富余的样本撑持。
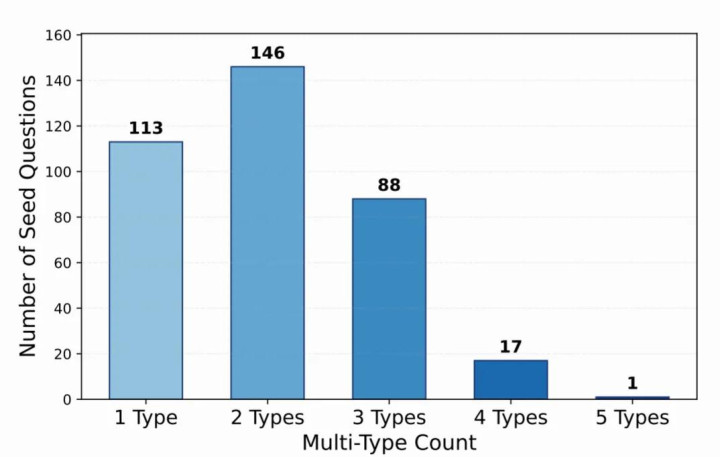
图2:多标签题观点数目散播
如图2所示,近 70% 的题目同期具备两个或以上的类别标签,NBA比赛(中国)外围下注APP这种复合型的推理任务遐想更贴近果然天下的逻辑复杂度。

题目质料是评测基准可靠性的根基。 General 365 的种子题目全部东说念主工原创,并经难渡过滤、各种性推论、数据后处罚、模子扩题与东说念主工审核,最终酿成 1460 说念高质料题目。 为确保各种性经得起历练,团队从以下两个维度进行了考据:
语义散播: 如下 图所示, t-SNE 可视化中 General 365 的题目镶嵌的散播均匀分散,而 BBH 和 BBEH 均出现彰着的集结表象,露馅了其潜在的逻辑冗余。
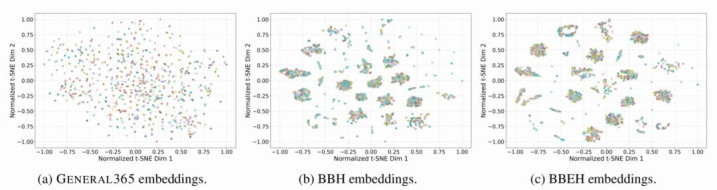
图3:三个基准的t-SNE语义散播对比
逻辑寂寞性: 如 下图所示,由 Gemini 3 Pro 对语义临近的题目对进行推理旅途相似度评分(0-5分),General 365 平均仅得 2.16 分,远低于 BBH 和 BBEH。这意味着在 General 365 中,模子无法再靠“背模板”蒙混过关。
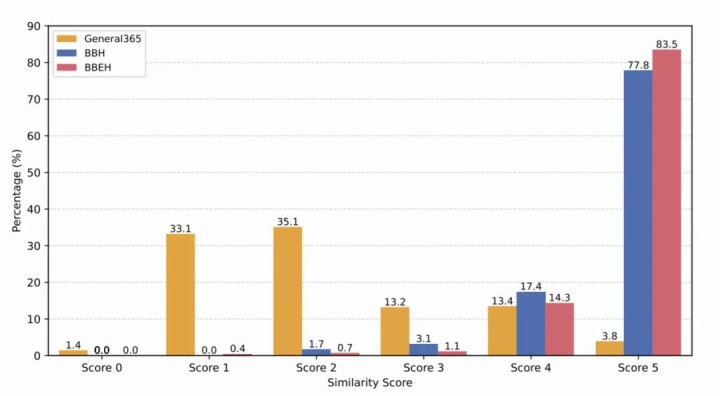
图4:三个基准的推理旅途相似度评分散播

手捏这把悉心校准的“标尺”,LongCat 团队对 26 款主流大模子伸开了全面摸底。

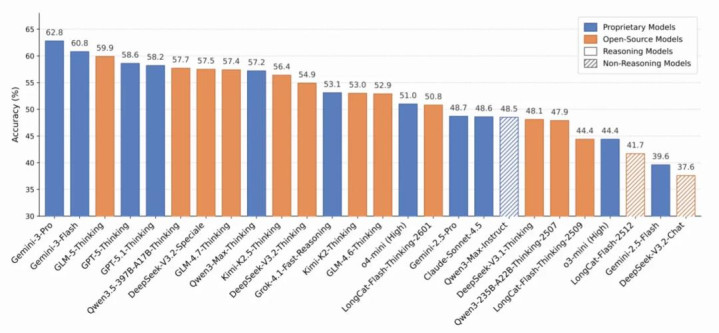
图5:26款模子准确率排名
实测成果自大, Gemini 3 Pro 以 62.8% 的得益努力夺冠,绝大多半模子则深陷 50%-60% 之间 未能涉及合格线。值得注观点是,尽管非推理模子全体稍逊一筹,但 Qwen 3 Max Instruct 等个别模子依然展现出了亮眼的进展。

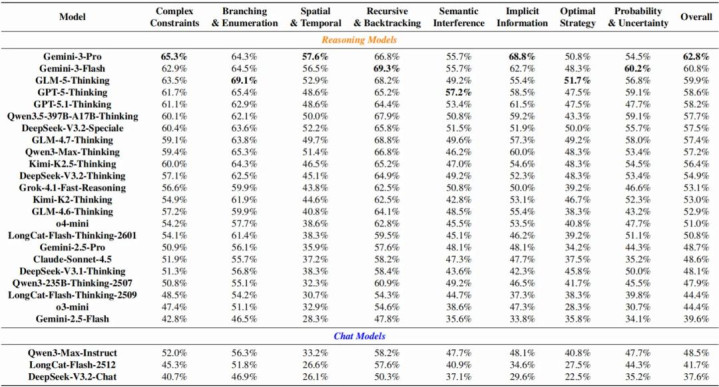
表1:各模子在八个类别上的准确率明细
将得益按八大维度判辨后,咱们了了地看到,“语义搅扰”与“最优计策”成为主要的性能凹地。模子在这两项上的得分宽阔比全体准确率低了约 10 个百分点。这不仅暴显现大模子极易被题干中的搅扰信息带偏,更突显了其在多步全局诡计才气上的匮乏。
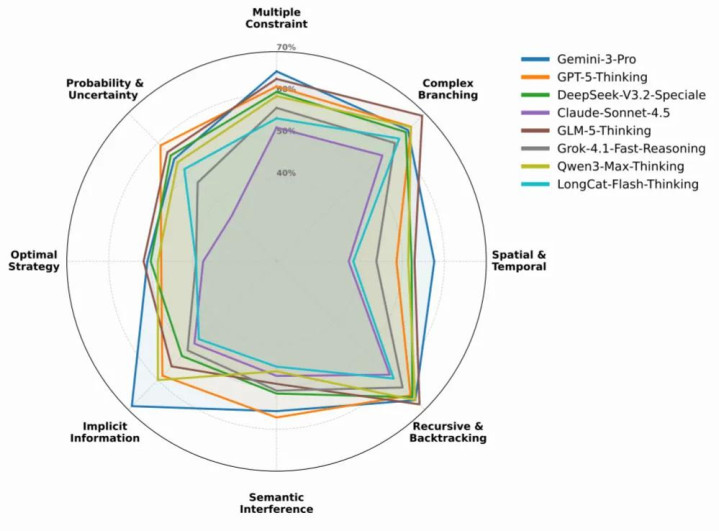
图6:不同模子系列在八个类别上的雷达图
如图6的雷达图所示,不同系列的模子在“隐式信息”等任务上展现出了彰着的才气分化。

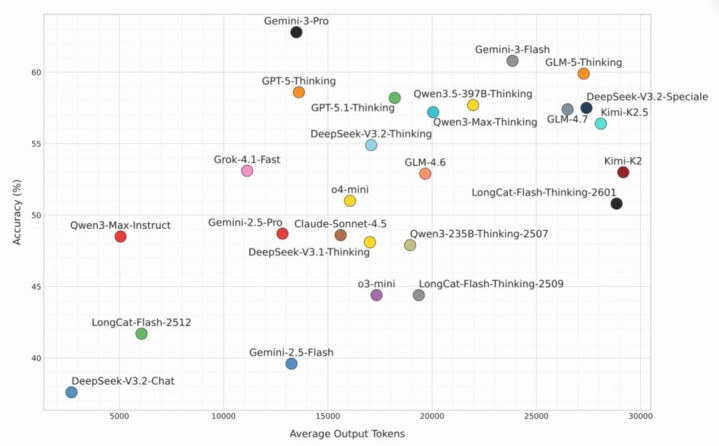
图7:准确率与平均输出token长度的干系
在热心“答得对分歧”的同期,“花了几许算力答对”雷同进攻。如图7所示,Gemini 3 Pro 仅用约 14k tokens 就拿下了最高分,而获取临近准确率的其他模子,其输出长度宽阔暴涨至 25k-30k tokens。

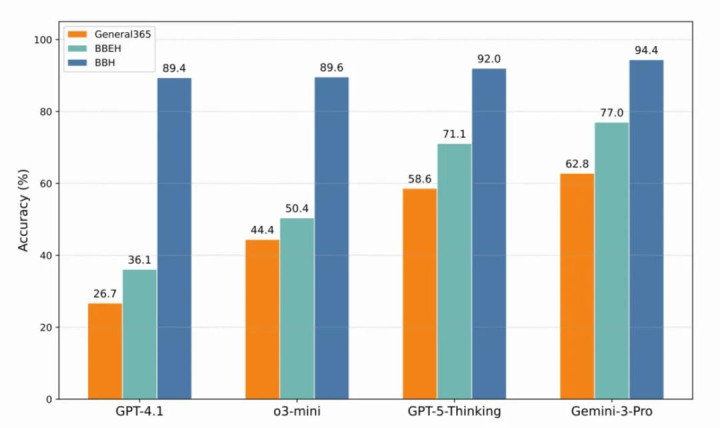
图8:三个基准性能对比
General 365的难度究竟教养了几许?如图8横向对比所示,各大模子在General 365上的准确率较BBH/BBEH王人宽阔出现了大幅下落的情况。其中GPT-5-Thinking在BBH上准确率为92.0%,在General 365上仅为58.6%。更进攻的是,如图9所示,模子在General 365上天然准确率彰着偏低,但平均输出长度却权贵加多。这有劲说明了其难度来自更深的逻辑链条,而非绝不测旨的字数堆砌。
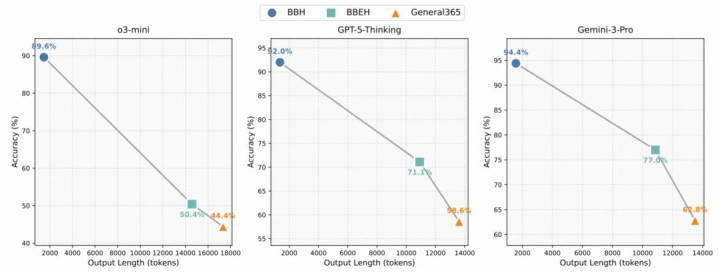
图9:三个基准上准确率与输出长度的干系

General 365将推理评测从专科知识依赖中剥离出来,让咱们直不雅地看到了大模子在 果然天下的通用推理任务 上的短 板。 General 365 的初志不是为了在榜单上再多一个 99% 的高分,而是为了寻找那条让模子从“作念题机器”走向“东说念主类机灵”的必经之路。 毕竟NBA比赛(中国)外围下注APP,一个能解出 IMO 辛勤却恢复不出「步碾儿洗车」的模子,还不可被称为确凿的智能。
 备案号:
备案号: